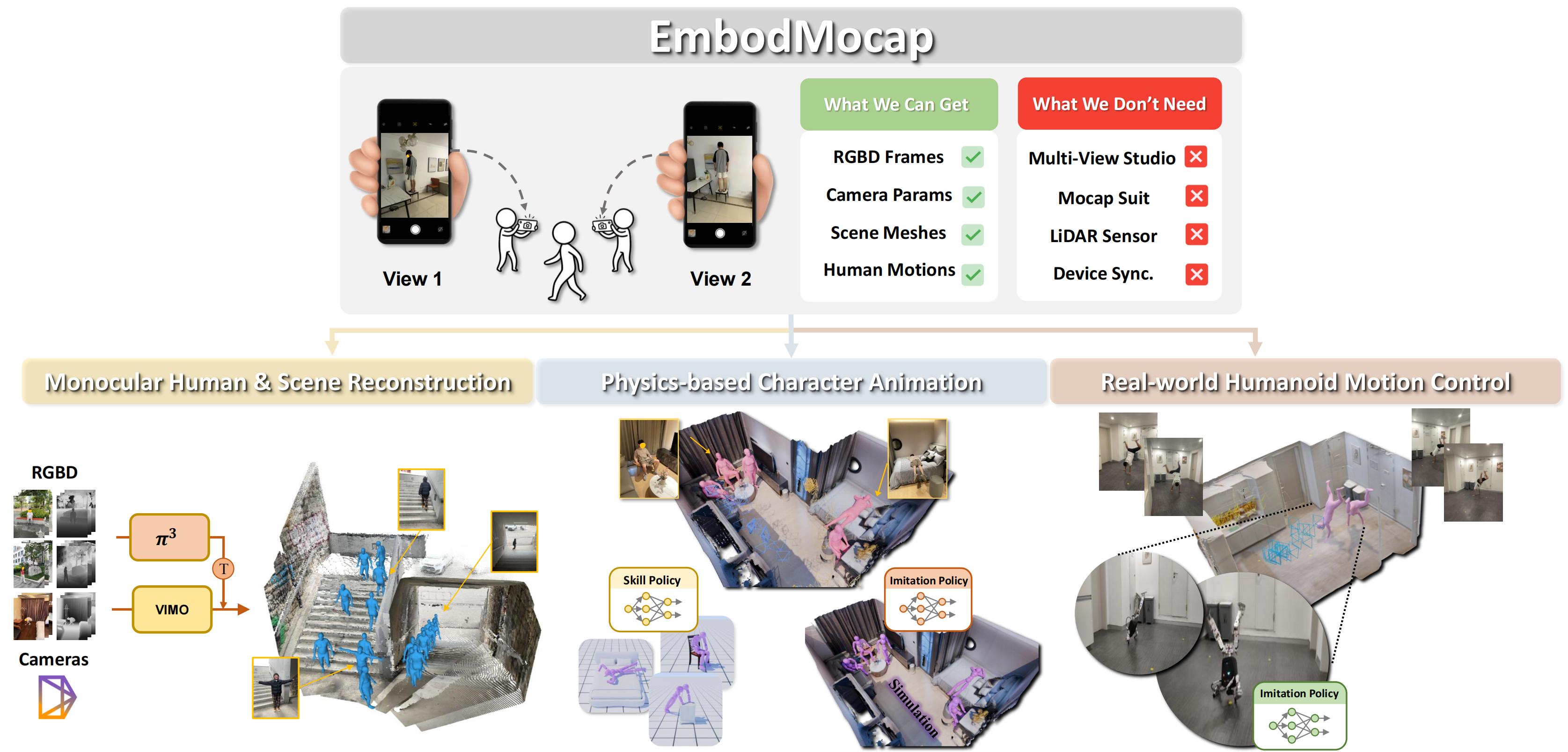
With the maturation of differentiable physics, its role in various downstream applications—such as model-predictive control, robotic design optimization, and neural PDE solvers—has become increasingly important. However, the derivative information provided by differentiable simulators can exhibit abrupt changes or vanish altogether, impeding the convergence of gradient-based optimizers. In this work, we demonstrate that such erratic gradient behavior is closely tied to the design of contact models. We further introduce a set of properties that a contact model must satisfy to ensure well-behaved gradient information. Lastly, we present a practical contact model for differentiable rigid-body simulators that satisfies all of these properties while maintaining computational efficiency. Our experiments show that, even from simple initializations, our contact model can discover complex, contact-rich control signals, enabling the successful execution of a range of downstream locomotion and manipulation tasks.