Bodyformer: Semantics-guided 3D Body Gesture Synthesis With Transformer
Abstract
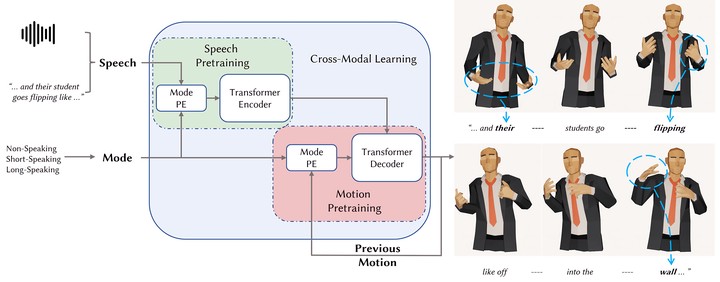
Automatic gesture synthesis from speech is a topic that has attracted researchers for applications in remote communication, video games and Metaverse. Learning the mapping between speech and 3D full-body gestures is difficult due to the stochastic nature of the problem and the lack of a rich cross-modal dataset that is needed for training. In this paper, we propose a novel transformer-based framework for automatic 3D body gesture synthesis from speech. To learn the stochastic nature of the body gesture during speech, we propose a variational transformer to effectively model a probabilistic distribution over gestures, which can produce diverse gestures during inference. Furthermore, we introduce a mode positional embedding layer to capture the different motion speeds in different speaking modes. To cope with the scarcity of data, we design an intra-modal pre-training scheme that can learn the complex mapping between the speech and the 3D gesture from a limited amount of data. Our system is trained with either the Trinity speech-gesture dataset or the Talking With Hands 16.2M dataset. The results show that our system can produce more realistic, appropriate, and diverse body gestures compared to existing state-of-the-art approaches.